Referral Notes:
- Clinical research depends on manual data collection and analysis, which is often laborious, time consuming, and inefficient.
- Neuro DataHub is an AI-driven organizational model designed by NYU Langone’s medical IT department to provide specialized data services for neurosurgical research.
- The model could be replicated for any clinical research or quality improvement program seeking to improve data accessibility and research capabilities.
Clinical research and quality improvement often requires the manual extraction of data from electronic medical records (EMRs), which is a slow, inefficient, and laborious process.
Furthermore, as neurosurgical practices are increasingly being integrated into large health systems, research efforts may be hindered by difficulties accessing data in centralized EMR systems.
To solve this problem, researchers and medical IT specialists from NYU Langone Health came together to develop a new artificial intelligence (AI)-backed service model, called Neuro DataHub, designed to democratize access to centralized data for neurosurgical research. The model was published in Neurosurgery Practice in December 2025.
“Neuro DataHub represents a paradigm shift in how neurosurgeons access institutional data and data-related services.”
Eric K. Oermann, MD
“The deployment of Neuro DataHub represents a paradigm shift in how neurosurgeons access institutional data and data-related services,” says neurosurgeon Eric K. Oermann, MD, who developed the model in collaboration with John G. Golfinos, MD, chair of the Department of Neurosurgery, and members of NYU Langone’s medical center information technology (MCIT) team, led by Nader Mherabi.
Democratizing Access to Centralized Data
“Datacores” are typically centralized services within IT departments used to provision data resources for the institution.
While datacores help to aggregate and provide access to data across large medical centers, Dr. Oermann explains that, from a neurosurgical standpoint, personnel often lack domain expertise and medical knowledge. This poses a barrier to interfacing with clinicians for clinical research and quality improvement applications.
In contrast to the datacore model, MCIT has implemented a federated model of data access. Rather than relying on a single centralized team, this model is built around specialized data hubs—groups with expertise in accessing and processing domain-specific clinical data.
To further support the neurosurgery department, Dr. Oermann, Alex Low—NYU Langone’s director of research data hubs—and colleagues in MCIT came up with an idea: hire an expert computer scientist and teach them the “language” of neurosurgery.
Xu Han, MS, who joined NYU Langone in 2024 and currently lead’s the Machine Learning Engineering team, helped found the Neuro DataHub and served as an initial bridge between the Department of Neurosurgery and MCIT. With deep expertise in how to engineer, tune, and deploy AI tools to search the centralized data bank, she can deliver fast and efficient responses to neurosurgery-specific questions.
“Our goal for this IT service is to remove key difficulties and barriers to clinical research,” Han explains. “We focus on addressing unique and specific neurosurgery-related questions.”
Neuro DataHub Workflow
The current Neuro DataHub service consists of one data engineer—initially Xu Han, now Qing Wen—working full-time and one clinical research coordinator working part-time. According to Dr. Oermann, the estimated cost of operating Neuro DataHub is $150,000 per year, consisting of predominantly salary and the associated time costs, not including the shared costs of maintaining NYU Langone’s enterprise Data Resources.
“This model could serve as a template for any clinical research program seeking to improve data accessibility and research capabilities.”
At its inception, no additional upfront costs were required since the service is based on already existing infrastructure, such as Epic, with hosted large language models. As the workflow queries data directly from local sources, no special licenses of permission are required.
“Data access and engineering resources are a fundamental service provided by the participating department to faculty members at cost,” explains Dr. Oermann.
The workflow was designed to emphasize the delivery of tailored data services to requesting faculty members. It consists of three primary phases: request submission, verification, and data delivery.
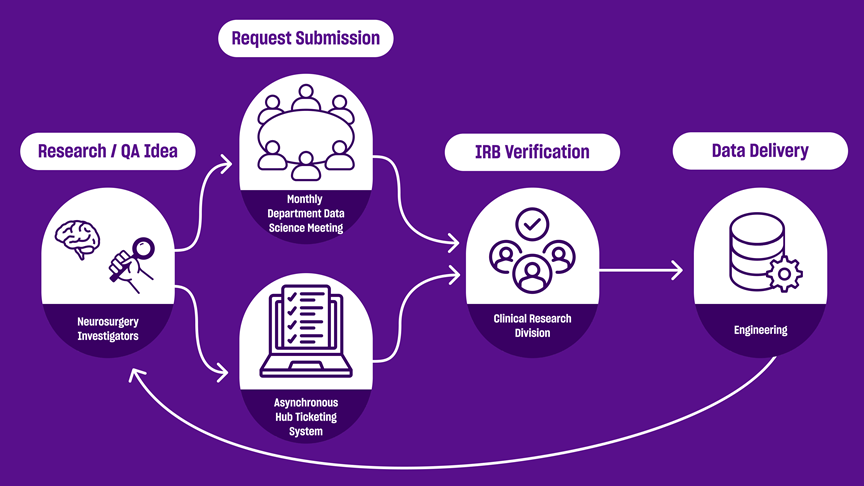
In the first year of operation, Neuro DataHub received a total of 39 data requests (~2.6 per month). Three of these requests were considered “basic,” meaning the information was stored in the columns of tables and therefore easily extracted. Twenty-two were complex, requiring careful querying of operative notes, and an additional 14 required natural language processing (NLP) to further clean and organize the data.
Overall, two complex requests included visualization services, and one NLP request included database creation. The average complete turnaround time across all requests was 36.5 days.
“Our workflow represents a shift from centralized to department-level data services, providing specialized support for neurosurgical research,” says Dr. Oermann.
Broader Research Applications
Beyond neurosurgical research, Dr. Oermann believes that Neuro DataHub could be replicated across organizations, where specialized departmental data hubs serve as intermediaries between datacores and clinical departments.
“This model could serve as a template for any clinical research program seeking to improve data accessibility and research capabilities,” Dr. Oermann says.